MySQL Drop Truncate Lock Bug
When you DROP or TRUNCATE a table or partition in MySQL or MariaDB and you have a large buffer pool, you may have noticed a complete server lock-up or stall of multiple seconds. Here is what you can do to work around this bug (MySQL bug #98869, MariaDB bug MDEV-9459).
Most people never notice this bug because their database servers have relatively small memory (and thus buffer pool) and the manifestation of the bug disappears in the noise on the monitoring graphs. But on large servers it quickly becomes obvious. Depending on the server’s CPU and memory bandwidth, the stall can be as much as 1 second per 32GB of RAM. If your buffer pool is 1TB that can mean your entire database locks up for as long as 30 seconds. That is going to cause serious problems with many highly concurrent interactive workloads, and database servers with hundreds of gigabytes of RAM are relatively common now. Our MySQL support specialists have been approached by different clients several times this year with problems that turned out to be manifestations of this bug, so we felt it was worth putting together a blog post to raise awareness of the issue.
Cause of the Bug
When a table is dropped, MySQL will perform a full scan of the buffer pool looking for pages that belong to the DROP-ed table. This locks the buffer pool, and stalls everything that uses it. With a small buffer pool, this is not noticeable. With a buffer pool of hundreds of gigabytes, this becomes obvious. With a buffer pool of terabytes, it becomes devastating.
Manifestation
Telemetry Dropouts
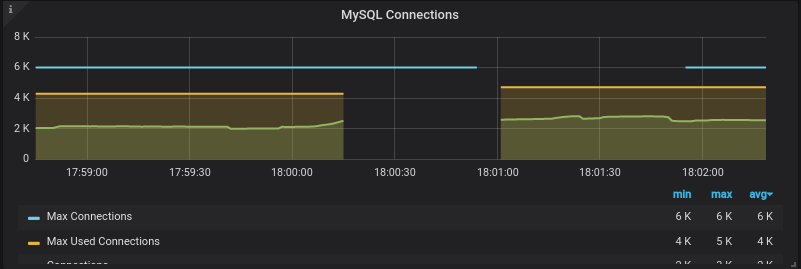
InnoDB buffer pool lock will have an impact on Prometheus’ mysqld_exporter ability to capture many of the metrics, and this will cause gaps in the data. This is what a such telemetry dropout looks like on a Grafana dashboard.
Thread Pileups
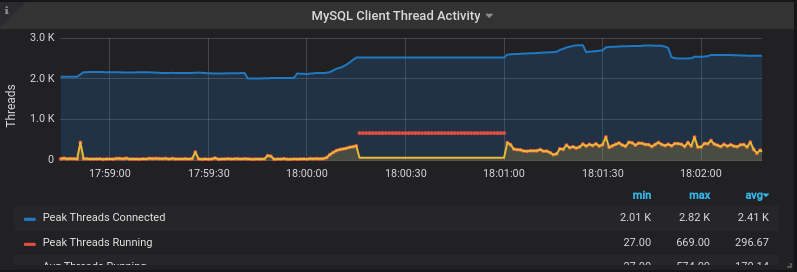
You will notice the number of connected and running threads spikes during the stall. This is because the running threads stall and don’t complete in a timely manner. Since they don’t complete, the connections stay around for longer and as more requests come in, the number of connected and running threads goes up. In this graph, you can see what it looks like combined with telemetry dropout.
Context Switching Drops
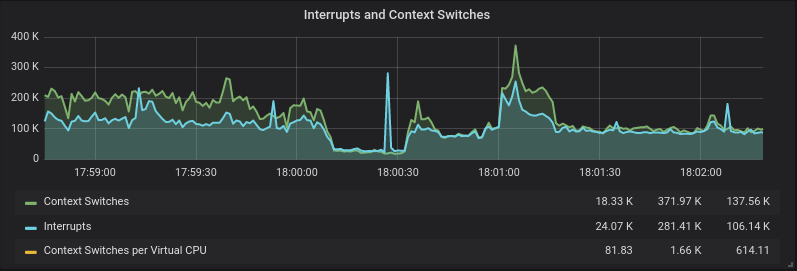
Since all of the threads are stalled and aren’t actually able to run running, the amount of context switches on the CPU goes down while the stall is occurring. This is what it looks like visually in Grafana.
Mitigations and Workarounds
The impact of this bug is particularly infuriating because it particularly affects some of the best practices around achieving best performance. For example, if you use a temporary table and a JOIN in order to avoiding a sub-select, when that temporary table is DROP-ed, either explicitly or implicitly (when the connection terminates), this bug will strike. If you are managing your data retention by partition rotation instead of DELETEs, DROP-ing a partition will trigger this bug.
There are several mitigations available, depending on the circumstances. None of them are without significant drawbacks, but with a large buffer pool, they are necessary.
DELETE before DROP-ing
If the table (or partition) is empty (0 rows) when DROP-ed, this bug doesn’t seem to manifest. So one way to evade the bug is to DELETE all the rows in a table or partition before DROP-ing it. This workaround is particularly anguishing if you are hitting this bug while you are deleting data by dropping a partition. You have partitioned your data specifically because DELETEs are slow and DROP is fast. And now you have to do a DELETE before a DROP in order to not cause a 30 second complete stall of your database.
Use non-InnoDB Storage Engine for Temporary Tables
If you are hitting this bug when using temporary tables (e.g. if you are using temporary table JOIN to avoid a large IN () clause, you can avoid having to use the first workaround (DELETE before DROP) by simply specifying that you want to use a non-InnoDB storage engine for the table, for example MyISAM, by specifying ENGINE=MyISAM in your CREATE TABLE statement. If you have a large code base and don’t explicitly specify the storage engine, you can change the default storage engine to MyISAM by adjusting the following configuration option:
default_tmp_storage_engine = MyISAM
Since MyISAM is not affected by this bug, switching temporary tables to MyISAM isn’t a bad option, since the biggest drawback of MyISAM is a near complete lack of ability to support write-concurrency. Since a temporary table only exists in the scope of a single session, there can never be any write concurrency, so this won’t matter.
Caveat: MyISAM also doesn’t support transactions, so if your code relies on being able to do a rollback of anything written to temporary tables, you will probably have to fall back on the DELETE-before-DROP mitigation.
Fix
The good news is that the fix for this has been implemented MySQL 8.0.23 and later and MariaDB 10.2.19 and later. Unfortunately, many deployments are still on MySQL 5.6 and 5.7, and likely to remain there for the foreseeable future, where the fix is not available.
